1 Croce, F., Andriushchenko, M., Sehwag, V., Debenedetti, E., Flammarion, N., Chiang, M., Mittal, P., & Hein, M. (2021). RobustBench: a standardized adversarial robustness benchmark. In Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2). https://openreview.net/forum?id=SSKZPJCt7B
Method Overview of GREAT Score
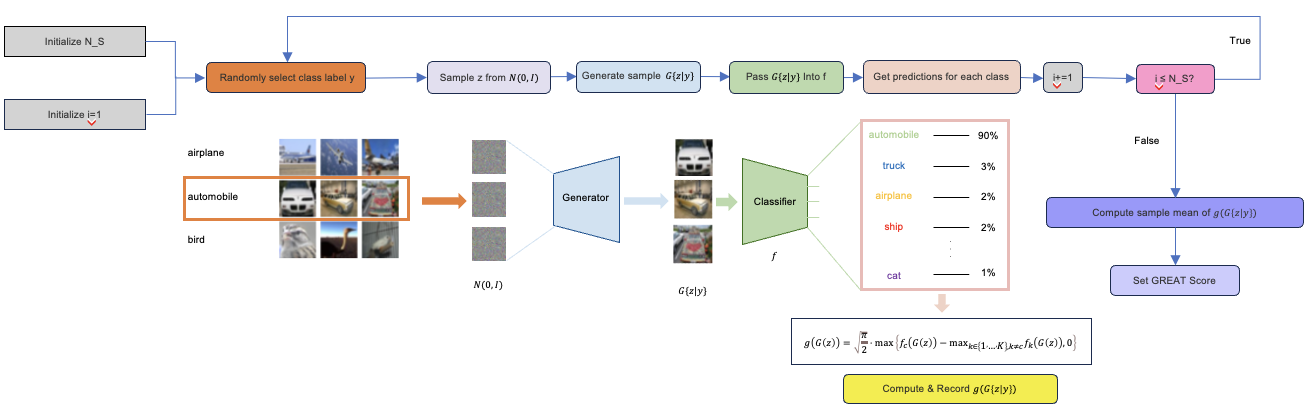
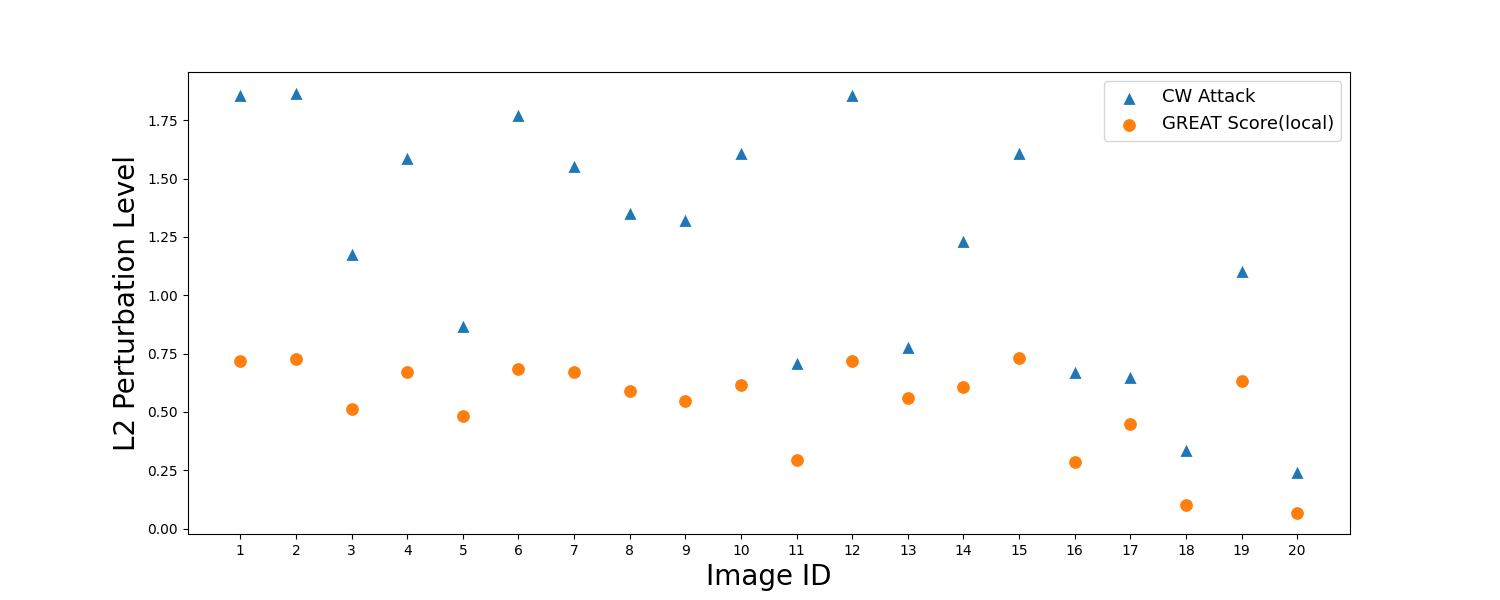
Figure 1. Overview of GREAT Score. The process involves three main steps: (1) Data Generation: We use a generative model to create synthetic samples. (2) Local Robustness Evaluation: For each generated sample, we calculate a local robustness score based on the classifier's confidence. (3) Global Robustness Estimation: We aggregate the local scores to estimate the overall robustness of the classifier. This method provides a certified lower bound on the true global robustness without requiring access to the original dataset or exhaustive adversarial attacks.